
I had this blog pretty well ready to post on Wednesday but decided to save the draft and have one more read through on Thursday before posting. However, on Thursday I went to the shops intending to post the blog on my return, but got distracted, and as it turned out, the delay was to my slight advantage. Late on Wednesday, and again on Thursday, Dan said what I have been saying privately for ages, and what prompted this blog in the first place, namely, that lockdowns and restrictions will not ‘drive the numbers down’! So, with increased confidence that my premise is correct, even if my opinion on the actual mechanism is not quite correct, I shall now hit the ‘publish’ button and say publicly what has been in my mind for some time. Please read on!
For nearly two years now we have been in and out of lockdown as our political leaders grapple with the Covid 19 pandemic. They tell us that they take, and follow, the advice they receive from their chosen medical advisors; but each State and Territory appears to take a different approach, so I can only assume that medical opinion must vary, depending on which side of the State border the advisor’s salary originates. The recent emergence of the Delta strain is an interesting example of these differences. Gladys tells us over and over again, ad nauseum, that “the new Delta strain is the most infectious and dangerous strain yet”. And then she tries to flick it away with a feather duster, a strategy presumably advised, or at least approved, by her medical advisors. At the other extreme, Dan gets out and wields the baseball bat, again, presumably, on the advice of his advisors. So, the question is, ‘is either, neither or both strategies the most appropriate response”?
In my previous blog I indicated that in this one I would set out my opinion on the rise and fall of successive waves of covid infections, but in order to understand the theory, it is first necessary to have a bit of a grasp on the way genetics works. So, I shall start with some very rudimentary molecular genetics, which can be found in any number of school-level science books.
We all know that the genetic code for humans and all other forms of complex life is contained in their DNA. Fewer people will be aware that DNA comprises 4 relatively simple components called bases, known by the initial letter of each of their names, Adenine, Cytosine, Thymine, and Guanine. They are arranged on a back-bone of deoxyribose, and the chains form a double helix, with C on one chain, paired with G on the other, and likewise, A and T are paired. In this illustration I have shown here only 6 bases in each strand, but in reality, they are many thousands of bases long, and contain every scrap of information required for life.
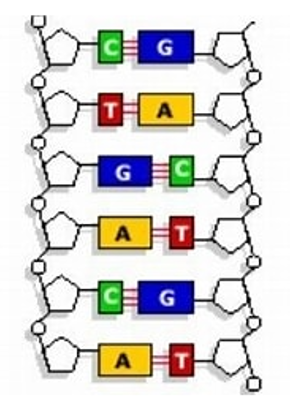
As well as ‘stop’ and ‘start’ signals, punctuation marks and so forth, triplet groups of consecutive bases code for each of the 21 or so amino acids that comprise our proteins. Thus, such a sequence might be A-C-T-G-T-T-C-G-A-T-A-G- (etc etc hundreds of bases long), with each group of three representing one amino acid. Now, if we take the same sequence but change just one base in the whole string thus, A-C-T-G-G-T-C-G-A-T-A-G- a different amino acid will be inserted into the protein, resulting in its having properties different to the original. In other words, a variant is created.
Before I leave the DNA, I will just explain that DNA is replicated in our cells when they divide so each of the new cells will have a complete copy of the entire genome. Genome copying is carried out by the DNA-dependant DNA polymerase enzyme. ‘DNA polymerase’ refers to the enzyme’s ability to assemble or polymerise new DNA strands and ‘DNA-dependant’ means it does this using the existing DNA as a template. But to unlock the code and translate it into protein, it must first be transcribed into an RNA ‘messenger’, referred to as mRNA. This is facilitated by the enzyme DNA-dependant RNA polymerase. The mRNA is picked up by sub-cellular organelles called ribosomes, which effect the translation into protein.
Human DNA is a very stable double-stranded molecule, and accordingly variations (ie, base substitutions) are relatively rare.
Now, back to Covid! Covid 19 is one of the very many ‘coronaviruses’, all of which have single-stranded RNA (note, not DNA) as their genetic material. This RNA is wrapped in a complex coat of lipids and proteins, including the much-referred to “spike protein” along with the less-referred to RNA-dependant RNA polymerase enzyme, which is also encoded in the RNA. This is absolutely essential to the replication of the virus, as our cells do not have an in-house supply of RNA-dependant RNA polymerase, without which, the virus cannot replicate. Hopefully that it not too confusing!
So, the Covid 19 virus has a single strand of RNA as its code; essentially the same make-up as DNA but the bases are on a backbone of Ribose (hence RNA), rather than Deoxyribose (DNA). The other difference, which is not significant here, is that three of the bases in RNA are the same A, C, and G, but the fourth is U rather than T. But the triplet groupings are still the codes for the amino acids. And when the virus infects a cell, the RNA is uncoated, it gets copied by the RNA-dependant RNA polymerase that the virus brought with it, and then behaves exactly the same as the normal cellular mRNA. That is to say, it gets picked up by a ribosome and translated into virus proteins including more of the polymerase enzyme. When there is the right mix of new viral RNA and proteins, they get assembled into complete progeny viruses, the cell breaks down, and the new virus particles are released to go and infect the next victim. (This intra-cellular translation of viral RNA to viral proteins is at the core of the Pfizer mRNA vaccine).
Now, the RNA-dependant RNA polymerase that the virus uses to copy its genome is more prone to introducing errors during copying than the DNA-dependant DNA polymerase our cells use and, unlike our cells, the virus does not have any means of correcting these errors. It is therefore far more likely that a wrong base will be inserted at some point in the viral genome each time the RNA is copied. That is to say, base “substitutions” can occur, leading to a different amino acid being used at one spot in the amino acid sequence resulting in a slightly different protein. Thus a ‘new variant’ is created. For the most part, these variant proteins make no difference to the virus so they are not of concern. Alternatively, they can be detrimental to the viral replication so we never see these particular variants in the community. Very occasionally, however, the protein change creates a variant that replicates better than the original virus or has other properties that aid its transmission from one person to another. These get labelled alpha, beta, gamma, delta and so on as the “Variants of Concern”.
Back to the Delta strain. This arose in India, and for some weeks a month or so ago, our news was full of the problems caused by Delta in India. We heard tales of woe from Australian citizens trapped in India and unable to return home. We were treated to much footage on television of funeral pyres in public parks and on the beaches, and we saw the devastating effects on an overwhelmed health system. Infections seemed to be spreading like wild-fire. But then, suddenly, and for no immediately apparent reason, India seemed to be no longer newsworthy, and it all disappeared from our television screens. At about the same time as this ‘disappearance’ of India, we found Delta here in Australia. As I mentioned in my opening paragraph, we were repeatedly told it was the “much more dangerous Delta strain”, as numbers rose despite the feather duster wielded by Gladys and the baseball bat swung about by Dan.
But what did happen in India, and what happened to the earlier “Variants of Concern” such as Alpha, Beta and Gamma?
This graph of Delta cases in India shows it very well
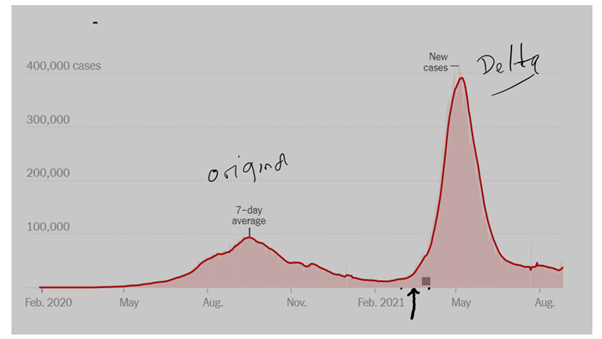
It is very clear that the kick-off in March 2021 was followed by huge growth in numbers until mid-May at which time the numbers started to fall; and they then fell at about the same rate as the rise, until they reached the original plateau by late June/early July. This fall can in no way be attributed to vaccinations, to the development of ‘herd immunity’, to lock-downs, to social distancing or to any other strategy. Co-incidentally, it was when the numbers started to fall that interest in the media seemed to wane along with the numbers.
My interpretation is that the same process of base substitution that leads to the emergence of the ‘Variants of Concern’ which cause so much havoc, is exactly the self-destructive process that leads to the demise of the variant. This degradation starts during the initial rise in infections and continues throughout the whole cycle to the end of the wave. It is when the number of defective progeny viruses of each infection cycle begins to exceed the number of non-degraded progeny that the numbers start to fall, each cycle from then on producing increasing numbers of defective progeny until the wave comes to it natural end. One hopes that we then get some breathing space before the next Variant of Concern appears.
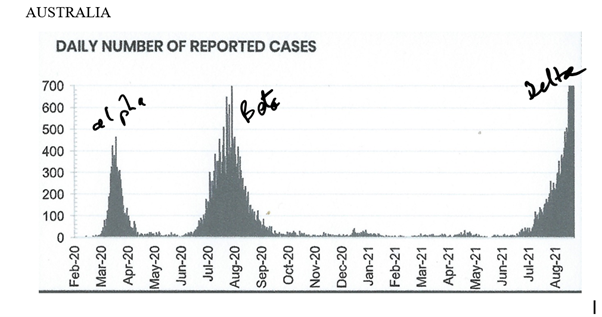
The mutations most likely to bring about the demise of a variant strain would be those that cause a piece to be missing from the part of the RNA that codes for the RNA Polymerase enzyme, leading to the production of a dysfunctional enzyme incapable of replicating the RNA. Consider the following sequence of events.
A cell is infected with normal virus and begins its replication. At some stage during the virus replication in a cell, a mutation occurs within the gene that encodes the RNA polymerase protein leading to a deletion of part of that sequence. Such mutations have been seen to occur in Coronavirus replication. When the virus particles are assembled, some will include the correct polymerase and some will include the defective polymerase. When the virus particles are released, a mixture of viruses with normal and defective polymerase enzymes may infect subsequent cells. The defective particles are incapable of producing the enzyme to replicate their RNA, but copies of that RNA can be replicated by the polymerase of the non-defective viruses. As the defective genome is slightly shorter than the normal genome it can be replicated faster and so there will be a slight increase in the proportion of defective genomes each time the virus replicates in new cells. Similarly, when the viruses are spread between people in the community, it is likely that they will be a mixture of non-defective and defective particles. The proportion of defective particles will increase over time as the defective genomes become dominant, and the process continues until eventually 50% of the progeny contain the defective genome and the wave begins to subside, as is shown in the above graphs. Note in the Australian graph, the delta curve is still heading north, but as I said in the Rambles One, it will not be long before the numbers head south!
Such a process not only attempts to explain why variant strains come and go as the Delta strain has in India, but it could also explain the ‘mystery’ of viral fragments turning up in wastewater even when no case has been detected. The degraded particles I have described are still infectious but are unable to replicate unless the cells are simultaneously infected with normal virus. But there will be occasions, particularly late in the wave, where people could be infected with only the degraded virus. These people would produce viral protein as normal, which they will shed into wastewater, but they will be the last of the line in that they cannot infect any more people. The PCR test which relies on detecting RNA will give negative results, and so the presence of the fragments remains a ‘mystery’.
So, what does it mean for us? I think that whilst it is not impossible, the number of infections currently in Australia is likely to be too small to create our own home-grown “Variants of Concern”, so our problems will continue to be imported variants escaping from quarantine. Following from that, it is clear that any traveller coming to Australia who has been infected overseas during the upward part of the curve will be bringing a very infectious virus, and our response should be swift and draconian because the wave could be vicious. However, someone arriving having been infected overseas during the downward part of the curve, would pose much less of a threat as the virus has already undergone a good deal of degradation by that time. Genomic sequencing, currently used to try to link cases, would be a very useful tool in determining how far the newly arrived infection has changed since the emergence of the Variant. This would further provide an estimate of how long the outbreak is likely to last.
The greatest threat will come from a new “Variant of Concern” that is so different, that our current vaccines might not afford the best immunity. In my explanations above, whilst concentrating on a mutation specifically effecting the RNA polymerase, I have referred to on-going mutations that could cause “Variants of Interest” to emerge, taking the full genome further away from the original. Now, suppose that toward the end of the natural life of any “Variant of Concern”, brought about by the defect in the polymerase, Sod’s Law was invoked, the original substitution reversed, and resulted in the repair and restoration of the polymerase to its proper and effective state. We now, suddenly, have a fully-functioning replicating genome ready to start making infectious progeny that are far enough removed from the original to earn its own status as a “new Variant of Concern”—-which will no doubt also earn the epithet of being “more dangerous and infectious than any previous variant”.
This is where the tweaking of the mRNA vaccines to keep up with the changes in the virus will be so important, and I would be pretty confident that Pfizer and others will already be working on that. However, it also means that we must continue to push ahead at the fullest speed possible with our vaccination programme, even when our current wave of Delta comes to its natural downward trend. That is to say, we must not become complacent. It is also vital that we push ahead with the development and construction of properly designed quarantine facilities to ensure that imported variants of concern cannot escape into the community.
Having said all of that, we could also take heart from the fact that the so-called “Spanish Flu” pandemic of one hundred years ago came to its natural end within two-three years with no help from vaccines, high-tech clinical interventions, lock-downs etc. Admittedly it claimed between 50 and 100 million lives from a global population of only 1.6 billion before it fizzled out, possibly by a mechanism not unlike the one I have described here by which our Variants of Concern have fizzled. (Bear in mind that flu is also an RNA virus). But of course, it also could have been due to the development of ‘herd immunity’ since there was very little done in those days to reduce the spread. So far, Covid has claimed just under 5 million lives from a global total population of the order of 7.8 billion—-so we are getting out of this pandemic rather lightly compared to 100 years ago!
Whilst the basic DNA and RNA chemistry described above is very standard stuff to be found in any number of text books and journals, the mechanisms I have described by which the Covid variants such as Delta disappear are my opinions, developed by applying my own reasoning based on my experience with the RNA polymerase of influenza virus, and what I have gleaned from information already the public domain. I have no new evidence to support the theory, and I am certainly not stating it as established fact. However, I am a little miffed at the reluctance of our political leaders to admit that the most significant contributor to the end of the wave is probably the virus itself! If anyone reading this has any other view on the rise and fall of covid waves, or if you find anything not quite clear, I would love to hear from you. I think you can leave comments on the blog site.
